Jupyter NotebookでUnixコマンドを実行するときの注意点
はじめに
Jupyter Notebookにて一部のコマンドがうまく実行できなくて、スタックしたことがあり、
その際の備忘として記事を残します。
1.シェルの状態はすぐに棄却される
Unixコマンドで実行したシェルの状態は実行直後に棄却されます。
なので!cdでカレントディレクトリを変更しても反映されません。
!pwd #出力:User/xxxx/ !cd Users/xxxx/Documents/ !pwd #出力:User/xxxx/ #ディレクトリが変更されていない
2.ターミナルとは異なる環境変数が設定されている(パス含む)
これは実行環境にもよる気がするのですが、ターミナルでコードを実行する際に参照される環境変数(というかパス)と
Jupyter Notebookで実行する際に参照される環境変数は異なるようです。
自分はこれが原因でhomebrewにて追加したコマンドが実行できませんでした。
(1.の理由で、Unixコードで環境変数を更新して実行するのも不可能でした。)
!brew -help #出力:zsh:1: command not found: brew #コマンドが見つからないエラーが出る
ロビンソン(スピッツ)を分析してみる(Into~Bメロ)
はじめに
スピッツのロビンソンの楽曲分析をします。
機械学習ではなく、純粋なコード進行の分析です。
イントロ
Key = AM/F#m
DM7 / C#m7 / F#sus4 / F#m
ⅣM7のコードで始まります。
メジャーコードでありながら、構成音の3,5,7度を取り出すとマイナートニック(Ⅵm)になるので、
曲の出だしに持ってくると調の長短が曖昧になるコードなのかな、と解釈しています。
私の好きな楽曲だと、以下の曲がⅣM7始まりです。
いずれも都会的でおしゃれな感じをこのコードで演出しているのかな、と思います。
Room335 / Larry Carlton
Just the Two of Us / Grover Washington Jr.
フライディ・チャイナタウン / 泰葉
Aメロ
A / Bm7 / E / F#m
D / A / D / E
登場するコードはいずれもダイアトニックであり、メロディもトニック周辺の音だけで構成されています。
少しトリッキーな進行のBメロとの対比になっていると思います。
Bメロ
C#m7 / F#m / Bm7 / E7
C#m7 / F#7 / Bm7 / E7 C#7
3625のターンアラウンドが2回登場しており、2周目のF#7はBm7に対するセカンダリー・ドミナントになっています。
この部分はメロディにもA#(#Ⅰ)が登場していて、サビに向けて緊張感をうまく高めています。
ラスト1小節はサビに向けて緊張感がピークになる部分です。
E7(V7)からA(Ⅰ)と行きたいところですが、あえてC#7(Ⅲ7)に向かって緊張感を引き伸ばしています。
C#7からはF#m(Ⅵm)と行きたいところですが、サビ頭のD(Ⅳ)に解決して、ここでも調の長短が曖昧になる工夫が垣間見れます。
メロディもサビ頭のF#(Ⅵ、マイナードミナント)に対してBメロラストの音はE##(#V)であり、マイナーに解決した感を演出しつつも、
解決するコードはメジャーコードのDとなっており、ここも調の長短の曖昧さにつながっています。
おわりに
サビも気が向いた時に分析したいと思います。
今回はここまで。
Edinet APIを使ってみる(書類取得API編 その1)
はじめに
Edinet APIをPythonで使ってみる。
書類一覧APIと書類取得APIの2つがあるが、この記事では書類取得APIについて扱う。
まずは叩いてみる
import requests doc_id = 'S100LF3R' #取得したい書類の書類管理番号 res = requests.get('https://disclosure.edinet-fsa.go.jp/api/v1/documents/'+doc_id+'?type=1') res.content #出力 #b'PK\x03\x04\x14\x00\x08\x00\x08\x00\xb2N\x83T\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00_\x00\x00\x00XBRL/PublicDoc/0000000_header_jpcrp030000-asr-001_E03054-000_2021-03-31_01_2021-05-28_ixbrl.htm\xed][s\x1b\xc7\x95~\xcf\xaf@\xd1U\x9b\x97...'
仕様書の通り、取得したい書類のバイナリデータを取得できたので、
これをzipファイルに書き出す。
import shutil with open(f'{doc_id}.zip','wb') as f: f.write(res.content)
これでカレントディレクトリに取得したい書類のzipが保存される。
提出本文書のxbrlのみを取り出す。
NLPで使いそうな提出本文書のxbrlのみを取り出してみる。
必要になる処理は主に以下の通り。
・カレントディレクトリ階下のtempフォルダにzipを保存&解凍
・中身のxbrlファイルをxbrlフォルダに移動
・tempフォルダに保存したzip&解凍後のファイルを削除
・for文で複数文書を取得
import requests import shutil import glob import os doc_ids = ['S100LF3R','S100LFJ8','S100LGMY']#取得したい書類の書類管理番号 for doc_id in doc_ids: res = requests.get('https://disclosure.edinet-fsa.go.jp/api/v1/documents/'+doc_id+'?type=1') with open(f'./temp/{doc_id}.zip','wb') as f: f.write(res.content) shutil.unpack_archive(f'./temp/{doc_id}.zip', f'./temp/{doc_id}') xbrl_temp = glob.glob(f'./temp/{doc_id}/XBRL/PublicDoc/*.xbrl') os.rename(xbrl_temp[0], f'./xbrl/{doc_id}.xbrl') shutil.rmtree(f'./temp/{doc_id}') os.remove(f'./temp/{doc_id}.zip')
とりあえず今回はここまで。
Edinet APIを使ってみる(書類一覧API編 その2)
はじめに
Edinet APIをPythonで使ってみる。
書類一覧APIと書類取得APIの2つがあるが、この記事では書類一覧APIについて扱う。
前回の記事でとりあえず出力をPandas DataFrameに変換するところまで進めたので、
本記事ではもう少し実用的な内容を扱う。
results(提出書類ごとのサマリー情報)の期間取得
実際の運用では、特定の日付でなく期間の間に提出された書類を確認することが多い(と思う)。
なので、resultsを期間取得できるようにコードを書いてみる。
以下では2021/4/1~2021/6/30の期間でresultsを取得し、pandas DataFrameで縦結合している。
日付の扱いにはdatetimeモジュールを使用し、変数deltaには期間の日数を代入。
import datetime as dt import pandas as pd import requests import json date_from = dt.date(2021, 4, 1) date_to = dt.date(2021, 6, 30) delta = (date_to - date_from).days df_rslt = pd.DataFrame() for i in range(delta+1): date = date_from + dt.timedelta(i) res = requests.get('https://disclosure.edinet-fsa.go.jp/api/v1/documents.json?date='+str(date)+'&type=2') res_txt = res.text res_dict = json.loads(res_txt) res_rslt = res_dict['results'] df_date = pd.DataFrame(res_rslt) df_date['submitDate'] = str(date) df_rslt = pd.concat([df_rslt,df_date]) df_rslt.set_index(['seqNumber','submitDate'],inplace = True) df_rslt
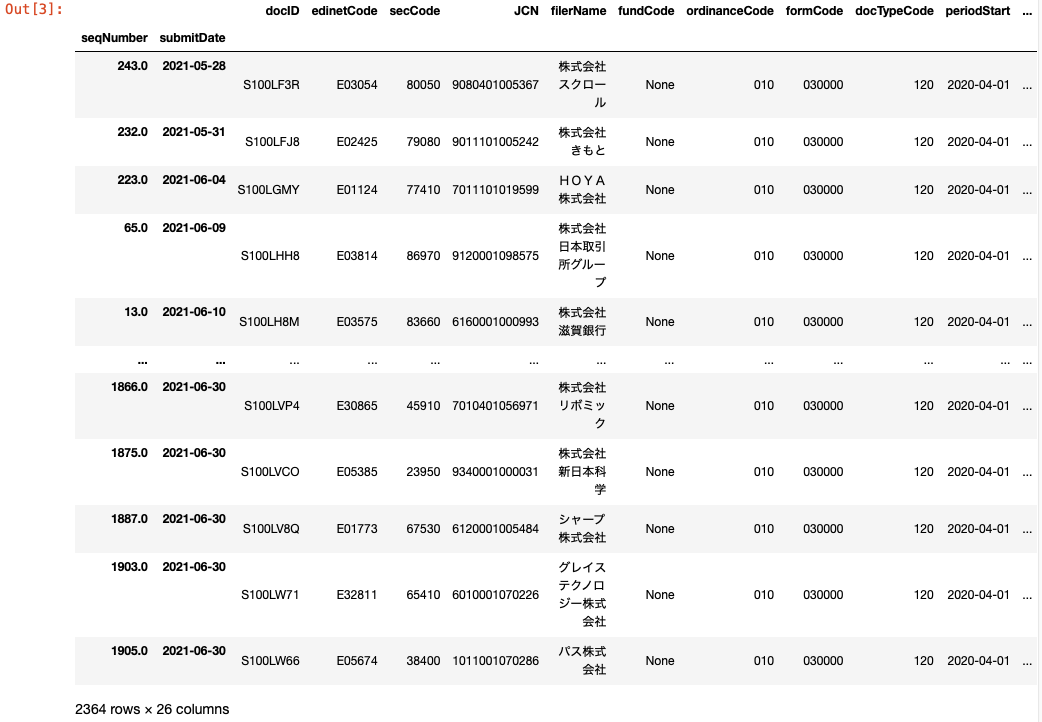
出力はこんな感じ。

特定の条件に該当する書類のみを抽出
このままだと選択期間に提出されたすべての書類がDataFrame上に存在することになるので、
分析に使えそうな以下の条件で抽出をかけてみる。
・決算日:2021/3/31
・提出書類:有価証券報告書
・対象企業:上場会社
有価証券報告書の提出期限は決算日後3ヶ月なので、抽出期間は上記のままでOK。
df_ar = df_rslt[(df_rslt['edinetCode'].isnull() == False) & (df_rslt['formCode'] == '030000') #様式コード:有価証券報告書 & (df_rslt['docTypeCode'] == '120') #書類種別コード:有価証券報告書 & (df_rslt['ordinanceCode'] == '010') #府令コード:企業内容等の開示に関する内閣府令 & (df_rslt['periodEnd'] == '2021-03-31') #決算日:2021/03/31 & (df_rslt['secCode'].notnull())] #証券コード:nullでない→上場企業
とりあえず今回はここまで。
Edinet APIを使ってみる(書類一覧API編 その1)
はじめに
Edinet APIをPythonで使ってみる。
書類一覧APIと書類取得APIの2つがあるが、この記事では書類一覧APIについて扱う。
まずは叩いてみる
pythonからgetメソッドでAPIを叩く。
出力がJSONフォーマットでそのままだと見づらいのでdict型に変換。
import requests import json date = '2022-03-09' response = requests.get('https://disclosure.edinet-fsa.go.jp/api/v1/documents.json?date='+date+'&type=2') res_txt = response.text res_dict = json.loads(res_txt)
出力はこんな感じ。
metadataに指定した日付にEdinetに提出された書類のサマリー情報が格納されている。
resultsには提出書類ごとの情報。
res_dict['metadata'] #出力 {'title': '提出された書類を把握するためのAPI', 'parameter': {'date': '2022-03-09', 'type': '2'}, 'resultset': {'count': 139}, 'processDateTime': '2022-03-10 00:02', 'status': '200', 'message': 'OK'}
res_dict['results'][0] #出力 {'seqNumber': 1, 'docID': 'S100N7NZ', 'edinetCode': 'E12444', 'secCode': None, 'JCN': '8010001114914', 'filerName': '三井住友トラスト・アセットマネジメント株式会社', 'fundCode': 'G04973', 'ordinanceCode': '030', 'formCode': '10A000', 'docTypeCode': '160', 'periodStart': '2021-06-10', 'periodEnd': '2022-06-09', 'submitDateTime': '2022-03-09 09:00', 'docDescription': '半期報告書(内国投資信託受益証券)-第16期(令和3年6月10日-令和4年6月9日)', 'issuerEdinetCode': None, 'subjectEdinetCode': None, 'subsidiaryEdinetCode': None, 'currentReportReason': None, 'parentDocID': None, 'opeDateTime': None, 'withdrawalStatus': '0', 'docInfoEditStatus': '0', 'disclosureStatus': '0', 'xbrlFlag': '1', 'pdfFlag': '1', 'attachDocFlag': '0', 'englishDocFlag': '0'}
resultsの中身をpandas DataFrameに変換
先ほど取り出したresultsをpandas DataFrameに変換して中身を見やすくする。
あらかじめ出力をdict型に変換してあるので、変換はコード1行で可能。
このままだと列数が多いので、columns変数に必要そうな項目のリストを代入して列数を絞る。
import pandas as pd res_rslt = res_dict['results'] df_rslt = pd.DataFrame(res_rslt) df_rslt.set_index('seqNumber',inplace=True) columns = ['docID', 'edinetCode', 'secCode', 'JCN', 'filerName', 'ordinanceCode', 'formCode', 'docTypeCode', 'periodStart', 'periodEnd', 'submitDateTime'] df_rslt[columns].head()

とりあえず今回はここまで。
SQLいろいろ
はじめに
だいぶ更新をサボってしまっていたのですが、今後は自分の学習記録として週一くらいで更新できればと思います。
今回は以下の書籍でSQLについて色々学んだので、書籍内の演習の一部に対する自分の解答をまとめようと思います。
集中演習 SQL入門 Google BigQueryではじめるビジネスデータ分析(できるDigital Camp) - インプレスブックス
演習030
・メインクエリ
ランディングページと離脱ページの組み合わせ(concat(landing,'->',exit))をセッションカウントの多い順に並べています。
ユニークなcid, session_countの組み合わせがセッションカウントになるので、count(distinct)でセッションカウントを集計しています。
・サブクエリ
ランディングページと離脱ページの組み合わせを集計しています。
ウィンドウ関数のfirst_value,last_valueにてセッションカウント毎のランディングページ・離脱ページを取得しています。
select concat(landing,'->',exit) as landing_and_exit , count(distinct concat(cid, session_count)) as session from ( select * , first_value(page) over ( partition by cid, session_count order by date_time rows between unbounded preceding and unbounded following ) as landing , last_value(page) over ( partition by cid, session_count order by date_time rows between unbounded preceding and unbounded following ) as exit from sample.web_log ) where landing != exit group by landing_and_exit order by 2 desc limit 5
Word2Vecの出力をMDSで解釈してみる
はじめに
前回紹介したWord2Vecを用いた文章の分散表現をMDSで次元削減し視覚的に解釈可能にしてみます。
oryou-san.hatenablog.com
前処理
scikit-learnのdataset"fetch_20newsgroups"を学習用データとして用います。
Word2Vecの入力に適するように文章を単語毎に区切られたリストに変換し、記号は空白に置換します。
from sklearn.datasets import fetch_20newsgroups data = fetch_20newsgroups(remove=('headers', 'footers', 'quotes')) texts = [txt.replace('.', '').replace(',', '').replace('/', '').split() for txt in data.data] texts = [w for w in texts] print(texts[0]) # ['I', 'was', 'wondering', 'if', 'anyone', 'out', 'there', 'could', 'enlighten', ... , 'e-mail']
学習(Word2Vec)
前処理を施したデータをモデルに投入します。
単語の類似度をどの程度学習できたかを確かめるのに'windows'という単語ベクトルとコサイン類似度の高い単語を降順で出力してみます。
PC関係の単語がずらずらと出力されてきたのでモデルの学習が正常に進んだことを確認できました。
from gensim.models import Word2Vec model = Word2Vec(texts, min_count=1, seed=1) key = 'windows' for w in model.wv.most_similar(key, topn = 10): print(w) # ('Windows', 0.936229407787323) # ('drivers', 0.9341704845428467) # ('memory', 0.9085516929626465) # ('disks', 0.9075465798377991) # ... # ('bus', 0.8947420716285706)
単語の分散表現から文章トピックの分散表現を獲得
データセットに存在する単語の分散表現を獲得できたので、これを用いて文章トピックの分散表現を計算してみます。
以下の手順で計算しています。
1.文章に登場する単語のベクトルの算術平均を取り、これを文章の分散表現とする
2.トピックに登場する単語のベクトルの算術平均を取り、これをトピックの分散表現とする
import numpy as np vec_news = [np.average([model.wv[w] for w in txt], axis = 0) if txt != [] else np.zeros(100) for txt in texts] vec_topics = [] for i in range(20): tpc_i = [idx for idx,d in enumerate(data.target) if d == i] vec_topic = np.average(np.array(vec_news)[tpc_i], axis=0) vec_topics.append(vec_topic) vec_topics = np.array(vec_topics)
学習(MDS)
いよいよMDSに学習データを投入します。
先ほど獲得したトピック毎の分散表現(トピック数(20) * ベクトル次元数(100))から各トピック間のL2ノルムを計算します(トピック数(20) * トピック数(20))。
L2ノルム計算にあたってはブロードキャスト処理を用いて効率化しております。
(記事末尾に記載のサイト様を参考にしました。)
diffs = np.expand_dims(vec_topics, axis=1) - np.expand_dims(vec_topics, axis=0) dist = np.sqrt(np.sum(diffs ** 2, axis=-1)) from sklearn import manifold mds = manifold.MDS(n_components=2, dissimilarity="precomputed", random_state=1) pos = mds.fit_transform(dist)
結果を散布図にして出力
MDSにて2次元に圧縮されたトピックの分散表現を散布図に出力してみました。
トピックの大分類(7つ)を用いてドットを色分けしていますが、散布図上でも綺麗に色毎にまとまっているように見えます。
labels = data.target_names label_big = [label[:(label.find('.'))] for label in labels] %matplotlib inline import matplotlib.pyplot as plt x = pos[:,0] y = pos[:,1] for label in list(set(label_big)): label_idx = [i for i,l in enumerate(label_big) if l == label] plt.scatter(x[label_idx], y[label_idx], s=20) plt.legend(list(set(label_big))) plt.show()

参考